KMeans聚类算法
KMeans聚类:KMeans单词—-K(K个聚类中心)+Means(根据均值迭代聚类中心)
KMeans聚类算法是一种经典的聚类方法,属于无监督学习。它的主要目标是将n个样本划分到k个簇中,使得每个样本属于与其最近的均值(即簇中心)对应的簇,从而使得簇内的方差最小化。
K-Means算法的思想: 对给定的样本集,用欧氏距离(向量)作为衡量数据对象间相似度的指标,相似度与数据对象间的距离成反比,相似度越大,距离越小。
欧式距离计算公式:
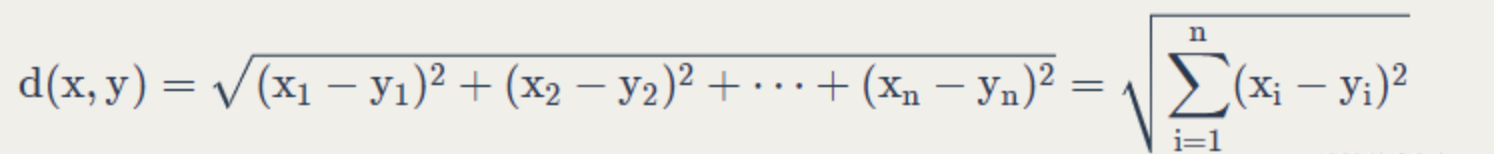
算法步骤
- 首先随机选择K个质心,有多少个质心最后就会有多少个簇
- 计算每个样本点到达K个质心的距离,如果距离比较近直接划分到这个簇
- 在分出的簇内部重新计算质心,通常是簇内所有点的均值,然后迭代进行分簇
- 检查算法是否满足停止条件,比如质心的变化小于某个阈值,或者连续迭代中簇的成员没有变化,或者达到预设的迭代次数
- 满足结束条件停止迭代